




隨著共建“一帶一路”進入高質量發展新階段,科技創新與合作將在其中發揮更關鍵的作用。上海人工智能實驗室(上海AI實驗室)通過研發先進數據智能技術,提供多語言語料庫等舉措,探索以人工智能賦能高質量共建“一帶一路”。
1月9日,上海AI實驗室聯合大模型語料數據聯盟成員發布了“萬卷·絲路”多語言預訓練語料庫,為多語言大模型訓練提供高質量數據支撐。
“萬卷·絲路”首期開源了包含泰、俄、阿、韓、越等五個語種的語料,總規模超1.2TB(單語種均超過150GB),Token總數超過300B,涵蓋使用上述語種國家地區的生活、百科、文化、新聞等七大領域數據。
開源鏈接:<a https:="" opendatalab.com"="" target="_blank" style="box-sizing: border-box; background: 0px 0px; transition: all 0.3s ease-in-out 0s; text-decoration-line: none; color: rgb(58, 90, 122); word-break: break-all;">https://opendatalab.com/applyMultilingualCorpus" target="_blank" style="word-break: break-all;">https://opendatalab.com/applyMultilingualCorpus
海量數據+細分領域,適應多樣化研究需求
數據是人工智能重要的基礎設施,數據質量是決定人工智能應用能力的關鍵因素之一。針對多語言語料庫發展不平衡、高質量語料短缺的研究現狀,上海AI實驗室開源了“萬卷·絲路”多語言語料庫。作為綜合性文本語料庫,“萬卷·絲路”采集了多個國家地區的網絡公開信息、文獻、專利等資料,數據總規模超1.2TB,Token總數超過300B(300 billion),處于國際領先水平。首期開源的語料庫主要由泰語、俄語、阿拉伯語、韓語和越南語5個子集構成,每個子集的數據規模均超過150GB。
基于“書生·浦語”智能標簽分類體系,上海AI實驗室研究團隊將每個語料子集細分為7個大類和32個小類,覆蓋歷史、政治、文化、房產、購物、天氣、餐飲、百科、專業知識等多類具有語言所在地特征內容,便于研究者根據具體需求檢索數據,并可適應不同研究領域多樣化需求。
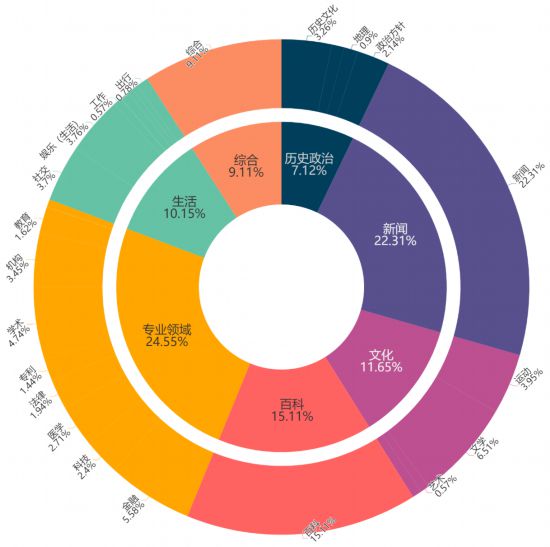
“萬卷·絲路”語料庫子集分類(共計7大類、32小類,圖表中僅展示了部分標簽)
專家標注+數據智能,兼顧安全與質量
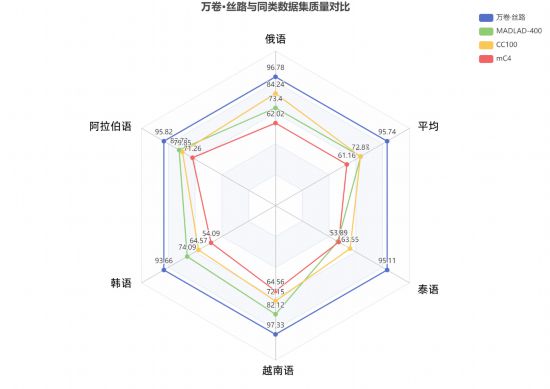
“萬卷·絲路”語料庫通過專家人工標注,確立了包含七個維度的文本數據質量評估體系,從完整性、有效性、可理解性、流暢性、相關性、相似性和安全性等方面保障數據的高標準與高質量。
通過使用基于大語言模型的數據質量評估開源工具——Dingo(https://github.com/DataEval/dingo),研究團隊從多維度對“萬卷·絲路”的數據質量進行了全面評估。結果表明,其五個子集均獲得優異的綜合評分,顯著優于同類語言語料庫。
為充分體現多語言特色、全面提升數據質量與適用性,發揮實驗室領先的數據處理能力優勢,研究團隊為“萬卷·絲路”設計一套精準化數據處理流程:
1.對網頁及非網頁數據進行標準化處理,統一數據格式,然后運用局部敏感哈希算法高效去重,降低冗余;
2.在安全性處理上,建立域名黑名單篩除不良網頁數據,構建多語言特色敏感詞表并結合語境評估,精準過濾有害內容,同時訓練語言安全模型,進行多維度不良內容檢測和篩選;
3.利用主題分類器對數據進行分類,優化知識域分布;
4.通過PPL初篩快速剔除低質量數據,再借助基于BERT的質量分類模型精準篩選高質量內容。
該流程有效融合多語言特點與行業通識技術,為多語言模型訓練提供了高質量、安全可靠的數據基礎。

萬卷·絲路數據處理流程
為評估“萬卷·絲路”數據集質量,研究團隊使用“萬卷·絲路”數據在開源基座上進行繼續預訓練,實驗結果顯示,使用“萬卷·絲路”后,模型在多語言內容理解及推理能力上的表現均獲得了提升。
中國大模型語料數據聯盟
由上海人工智能實驗室聯合中央廣播電視總臺、人民網、國家氣象中心、中國科學技術信息研究所、上海報業集團、上海文廣集團等10家單位聯合發起。為應對大模型發展對高質量、大規模、安全可信語料數據資源的需求,保障大模型科研攻關及相關產業生態發展,大模型語料數據聯盟于2023年7月6日世界人工智能大會開幕式上宣布成立,旨在通過鏈接模型訓練、數據供給、學術研究、第三方服務等多方面機構,聯合打造多知識、多模態、標準化的高質量語料數據,探索形成基于貢獻、可持續運行的激勵機制,打造國際化、開放型的大模型語料數據生態圈。
來源:上海人工智能實驗室
 掃一掃分享本頁
掃一掃分享本頁



















